Rice distribution
| Probability density function |
|
| Cumulative distribution function |
|
| Parameters | ν ≥ 0 — distance between the reference point and the center of the bivariate distribution, σ ≥ 0 — scale |
|---|---|
| Support | x ∈ [0, +∞) |
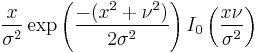 |
|
| CDF | 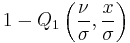
where Q1 is the Marcum Q-function |
| Mean | 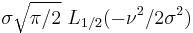 |
| Variance | 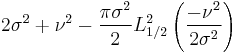 |
| Skewness | (complicated) |
| Ex. kurtosis | (complicated) |
In probability theory, the Rice distribution or Rician distribution is the probability distribution of the absolute value of a circular bivariate normal random variable with potentially non-zero mean. It was named after Stephen O. Rice.
Contents |
Characterization
The probability density function is
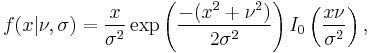
where I0(z) is the modified Bessel function of the first kind with order zero. When v = 0, the distribution reduces to a Rayleigh distribution.
The characteristic function is:[1][2]
![\begin{align}
\chi_X(t|\nu,\sigma) & = \exp \left( -\frac{\nu^2}{2\sigma^2} \right) \left[
\Psi_2 \left( 1; 1, \frac{1}{2}; \frac{\nu^2}{2\sigma^2}, -\frac{1}{2} \sigma^2 t^2 \right) \right. \\[8pt]
& \left. {} \quad %2B i \sqrt{2} \sigma t
\Psi_2 \left( \frac{3}{2}; 1, \frac{3}{2}; \frac{\nu^2}{2\sigma^2}, -\frac{1}{2} \sigma^2 t^2 \right) \right],
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/1207875f799b662a1b125f1c5541e26e.png)
where 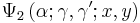 is one of Horn's confluent hypergeometric functions with two variables and convergent for all finite values of
is one of Horn's confluent hypergeometric functions with two variables and convergent for all finite values of  and
and 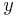 . It is given by:[3][4]
. It is given by:[3][4]
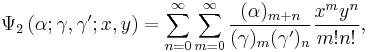
where
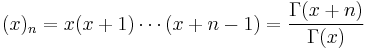
is the rising factorial.
Properties
Moments
The first few raw moments are:
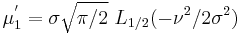
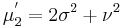
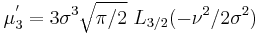
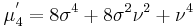
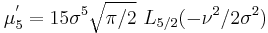
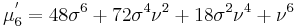
where Lq(x) denotes a Laguerre polynomial:
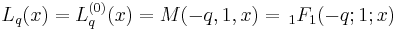
where 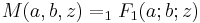 is the confluent hypergeometric function of the first kind.
is the confluent hypergeometric function of the first kind.
For the case q = 1/2:
![\begin{align}
L_{1/2}(x) &=\,_1F_1\left( -\frac{1}{2};1;x\right) \\
&= e^{x/2} \left[\left(1-x\right)I_0\left(\frac{-x}{2}\right) -xI_1\left(\frac{-x}{2}\right) \right].
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/6cb203976080f0189ebb813b6cb8f570.png)
Generally the moments are given by
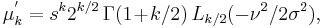
where s = σ1/2.
When k is even, the moments become actual polynomials in σ and ν.
The second central moment, equals the variance equation below (which is listed to the right):
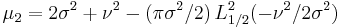
Note that 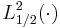 indicates the square of the Laguerre polynomial
indicates the square of the Laguerre polynomial 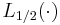 , not the generalized Laguerre polynomial
, not the generalized Laguerre polynomial 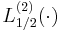 .
.
When the Rice distribution parameter ν = 0, the distribution becomes the Rayleigh distribution.
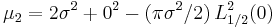
![L^2_{1/2}(0) = (e^0[(1-0)I_0(0)-0I_1(0)])^2](/2012-wikipedia_en_all_nopic_01_2012/I/1817932dbb95259c5dc9c9b976f1acf6.png)
![L^2_{1/2}(0) = (1 \cdot [I_0(0)])^2](/2012-wikipedia_en_all_nopic_01_2012/I/53d04c4c402feef551650974ab821d2e.png)
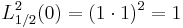
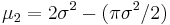
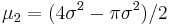
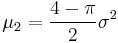
which is the variance of the Rayleigh distribution.
Related distributions
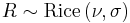 has a Rice distribution if
has a Rice distribution if 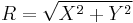 where
where 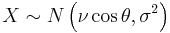 and
and 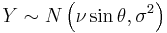 are statistically independent normal random variables and
are statistically independent normal random variables and 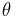 is any real number.
is any real number.
- Another case where comes from the following steps:
- 1. Generate
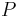 having a Poisson distribution with parameter (also mean, for a Poisson)
having a Poisson distribution with parameter (also mean, for a Poisson) 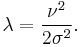
- 2. Generate
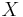 having a chi-squared distribution with 2P + 2 degrees of freedom.
having a chi-squared distribution with 2P + 2 degrees of freedom.
- 3. Set
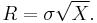
- If
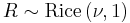 then
then 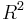 has a noncentral chi-squared distribution with two degrees of freedom and noncentrality parameter
has a noncentral chi-squared distribution with two degrees of freedom and noncentrality parameter 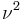 .
. - If
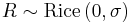 then
then 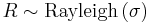 , and has an exponential distribution.[5]
, and has an exponential distribution.[5]
Limiting cases
For large values of the argument, the Laguerre polynomial becomes (see Abramowitz and Stegun §13.5.1)
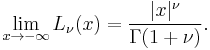
It is seen that as ν becomes large or σ becomes small the mean becomes ν and the variance becomes σ2.
Parameter estimation (the Koay inversion technique)
There are three different methods for estimating the Rice parameters, (1) method of moments, (2) method of maximum likelihood, and (3) method of least squares. The first two methods have been investigated by Talukdar et al.[6] and Bonny et al.[7] and Sijbers et al.[8]
Here the interest is in estimating the parameters of the distribution, ν and σ, from a sample of data. This can be done using the method of moments, e.g., the sample mean and the sample standard deviation. The sample mean is an estimate of μ1' and the sample standard deviation is an estimate of μ21/2.
The following is an efficient method, known as the "Koay inversion technique", published by Koay et al.[9] for solving the estimating equations, based on the sample mean and the sample standard deviation, simultaneously . This inversion technique is also known as the fixed point formula of SNR. Earlier works [10][11] on the method of moments usually use a root-finding method to solve the problem, which is not efficient.
First, the ratio of the sample mean to the sample standard deviation is defined as r, i.e., 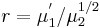 . The fixed point formula of SNR is expressed as
. The fixed point formula of SNR is expressed as
![g(\theta) = \sqrt{ \xi{(\theta)} \left[ 1%2Br^2\right] - 2},](/2012-wikipedia_en_all_nopic_01_2012/I/0f0f1943f3ddf223877fdeb1722ec3e0.png)
where is the ratio of the parameters, i.e., 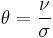 , and
, and 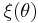 is given by:
is given by:
![\xi{\left(\theta\right)} = 2 %2B \theta^2 - \frac{\pi}{8} \exp{(-\theta^2/2)}\left[ (2%2B\theta^2) I_0 (\theta^2/4) %2B \theta^2 I_1(\theta^{2}/4)\right]^2,](/2012-wikipedia_en_all_nopic_01_2012/I/aaab0a3fdeff7718ef3e31603dcc4e6a.png)
where 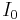 and
and 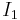 are modified Bessel functions of the first kind.
are modified Bessel functions of the first kind.
Note that is a scaling factor of 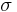 and is related to
and is related to 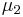 by:
by:
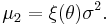
To find the fixed point, 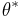 , of
, of 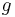 , an initial solution is selected,
, an initial solution is selected, 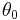 , that is greater than the lower bound, which is
, that is greater than the lower bound, which is 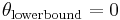 and occurs when
and occurs when 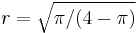 (Notice that this is the of a Rayleigh). This provides a starting point for the iteration, which uses functional composition, and this continues until
(Notice that this is the of a Rayleigh). This provides a starting point for the iteration, which uses functional composition, and this continues until 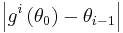 is less than some small positive value. Here,
is less than some small positive value. Here, 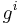 denotes the composition of the same function, ,
denotes the composition of the same function, ,  -th times. In practice, we associate the final
-th times. In practice, we associate the final 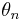 for some integer
for some integer  as the fixed point, , i.e.,
as the fixed point, , i.e., 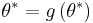 .
.
Once the fixed point is found, the estimates 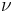 and are found through the scaling function, , as follows:
and are found through the scaling function, , as follows:
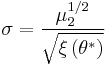 ,
,
and
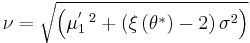 .
.
To speed up the iteration even more, one can use the Newton's method of root-finding as presented by Koay et al.[12] This particular approach is highly efficient.
The author has also provided an online calculator for computing the fixed point, which is also known as the underlying SNR from 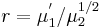 , the magnitude SNR. See the link here under the subtitle called HI-SPEED SNR Analysis I. Note that the number of combined channel is 1 for the Rician distribution.
, the magnitude SNR. See the link here under the subtitle called HI-SPEED SNR Analysis I. Note that the number of combined channel is 1 for the Rician distribution.
See also
- Rayleigh distribution
- Rician fading
- Stephen O. Rice (1907–1986)
Notes
- ^ Liu 2007 (in one of Horn's confluent hypergeometric functions with two variables).
- ^ Annamalai 2000 (in a sum of infinite series).
- ^ Erdelyi 1953.
- ^ Srivastava 1985.
- ^ Richards, M.A., Rice Distribution for RCS, Georgia Institute of Technology (Sep 2006)
- ^ Talukdar 1991
- ^ Bonny 1996
- ^ Sijbers 1998
- ^ Koay 2006 (known as the SNR fixed point formula).
- ^ Talukdar 1991
- ^ Abdi 2001
- ^ Koay 2006 (in Appendix A).
References
- Abramowitz, M. and Stegun, I. A. (ed.), Handbook of Mathematical Functions, National Bureau of Standards, 1964; reprinted Dover Publications, 1965. ISBN 0-486-61272-4
- Rice, S. O., Mathematical Analysis of Random Noise. Bell System Technical Journal 24 (1945) 46–156.
- I. Soltani Bozchalooi and Ming Liang, A smoothness index-guided approach to wavelet parameter selection in signal de-noising and fault detection, Journal of Sound and Vibration, Volume 308, Issues 1-2, 20 November 2007, Pages 253–254.
- Liu, X. and Hanzo, L., A Unified Exact BER Performance Analysis of Asynchronous DS-CDMA Systems Using BPSK Modulation over Fading Channels, IEEE Transactions on Wireless Communications, Volume 6, Issue 10, October 2007, Pages 3504–3509.
- Annamalai, A., Tellambura, C. and Bhargava, V. K., Equal-Gain Diversity Receiver Performance in Wireless Channels, IEEE Transactions on Communications,Volume 48, October 2000, Pages 1732–1745.
- Erdelyi, A., Magnus, W., Oberhettinger, F. and Tricomi, F. G., Higher Transcendental Functions, Volume 1. McGraw-Hill Book Company Inc., 1953.
- Srivastava, H. M. and Karlsson, P. W., Multiple Gaussian Hypergeometric Series. Ellis Horwood Ltd., 1985.
- Sijbers J., den Dekker A. J., Scheunders P. and Van Dyck D., "Maximum Likelihood estimation of Rician distribution parameters", IEEE Transactions on Medical Imaging, Vol. 17, Nr. 3, p. 357–361, (1998)
- Koay, C.G. and Basser, P. J., Analytically exact correction scheme for signal extraction from noisy magnitude MR signals. Journal of Magnetic Resonance, Volume 179, Issue 2, April 2006, Pages 317–322.
- Abdi, A., Tepedelenlioglu, C., Kaveh, M., and Giannakis, G. On the estimation of the K parameter for the Rice fading distribution, IEEE Communications Letters, Volume 5, Number 3, March 2001, Pages 92–94.
- Talukdar, K.K., and Lawing, William D. Estimation of the parameters of the Rice distribution, Journal of the Acoustical Society of America, Volume 89, Issue 3, March 1991, Pages 1193–1197.
- Bonny,J.M., Renou, J.P., and Zanca, M., Optimal Measurement of Magnitude and Phase from MR Data, Journal of Magnetic Resonance, Series B, Volume 113, Issue 2, November 1996, Pages 136–144.
External links
- MATLAB code for Rice/Rician distribution (PDF, mean and variance, and generating random samples)